تصاویر؛ همهچیز درباره هوشمصنوعی GPT-5: نابغهای که بازی میسازد یا احمقی که ۲+۲ بلد نیست؟

مدل جدید OpenAI از یک سو بازیهای پیچیده میسازد و از سوی دیگر در محاسبه ساده ریاضی میماند؛ این هوش مصنوعی احمق است یا نابغه؟
شرکت OpenAI سرانجام در تاریخ ۷ آگوست ۲۰۲۵ از GPT-5 رونمایی کرد: مدلی که خود شرکت ادعا میکند «هوشمندترین، سریعترین و مفیدترین مدل» آنها تا به امروز است و پیشرفتهای چشمگیری در زمینههای کدنویسی، نوشتن، ریاضیات، سلامت و درک بصری دارد.
بهگفتهی OpenAI، مدل GPT-5 یک سیستم یکپارچه است که میداند چه زمانی باید سریع پاسخ دهد و چه زمانی برای پاسخهای «سطح متخصص»، بیشتر فکر کند. این مدل برای همهی کاربران ChatGPT دردسترس است، اما مشترکین پلاس اعتبار بیشتری برای استفاده از مدل دریافت میکنند و مشترکین پرو به نسخهی GPT-5 Pro با توانایی استدلال بیشتر دسترسی خواهند داشت.
سم آلتمن، مدیرعامل شرکت، GPT-5 را با یک «متخصص در سطح دکترا» مقایسه کرد و آن را گامی مهم در مسیر دستیابی به هوش مصنوعی انسانگونه (AGI) خواند؛ یعنی همان هدفی که OpenAI از ابتدا برای رسیدن به آن تاسیس شده بود؛ اما تنها پس از ۲۴ ساعت از عرضهی اولیه، موجی از ناامیدی، تمسخر و خشم در شبکههای اجتماعی به راه افتاد: کاربرانی که اشتراکشان را لغو میکردند، منتقدانی که از ترکیدن حباب هوش مصنوعی میگفتند و نمونههای مضحکی از خطاهای فاحش مدل جدید که در شبکههای اجتماعی دستبهدست میشد.
یکی از جنجالیترین پستهای سابردیت ChatGPT با بیشاز ۶هزار رای مثبت و ۲هزار کامنت، این مدل را «افتضاح» خواند و از «پاسخهای کوتاه و ناکافی، لحن کلام آزاردهندهتر و تصنعی و شخصیت بیروح» آن انتقاد کرد. بسیاری از نبود مدلهای قدیمیتر مثل GPT-4o، محدودیتهای سختگیرانهتر در استفاده و «عملکرد ضعیفتر» مدل جدید گلهمند بودند و میگفتند GPT-5 برخلاف تبلیغات اغراقآمیز سم آلتمن، درواقع پسرفت کرده است.
کاربران از پاسخهای کوتاه و لحن تصنعی و شخصیت بیروح GPT-5 نسبتبه GPT-4o ناراضی بودند.
البته در سوی دیگر ماجرا، توسعهدهندگان و کاربران حرفهای هم بودند که با شگفتی از قابلیتهای خارقالعادهی GPT-5، از ساخت بازیهای کامپیوتری پیچیده در چند دقیقه و حل مسائل دشوار کدنویسی در یک چشم به هم زدن میگفتند.
اما واقعیت چیست؟ آیا GPT-5 واقعا «افتضاح» است و نسل بشر قرار نیست هرگز به AGI برسد؟ یا GPT-5 دقیقا در همان مسیری است که اوپنایآی از مدتها پیش برای آیندهی تکنولوژی ترسیم کرده و مشکل، جای دیگری است؟

GPT-5 دقیقا چیست و چه فرقی با مدلهای قبلی دارد؟
GPT−5 جدیدترین و پیشرفتهترین مدل هوش مصنوعی مولد شرکت OpenAI و جانشین GPT−4 است. گفته میشود این مدل «بسیار هوشمندتر، دقیقتر و سریعتر» از مدلهای قبلی خود است، طوریکه سم آلتمن اظهار داشت تجربهی بازگشت به GPT−4 پس از استفاده از GPT−5 برایش «بسیار رقتانگیز» بود.
GPT−5 دردسترس همهی کاربران، از کاربران رایگان ChatGPT گرفته تا مشتریان بزرگ شرکتی، قرار گرفته است. با این حال، سطح دسترسی و قابلیتها براساس نوع اشتراک کاربر متفاوت است:
- کاربران رایگان: به GPT−5 با محدودیت استفاده دسترسی خواهند داشت و پس از آن به مدل سبکتر «GPT−5−mini» منتقل میشوند.
- کاربران پلاس: اعتبار بیشتری نسبتبه کاربران رایگان دارند.
- کاربران پرو: دسترسی نامحدود به GPT−5 استاندارد و دسترسی به مدل قدرتمندتر «GPT−5 Pro» دارند.
- کاربران شرکتی/آموزشی/تیم: مدل پیشفرض آنها GPT−5 خواهد بود.
مدل قدیمی
مدل جدید جایگزین
|
GPT-4o |
GPT-5 main |
|
GPT-4o-mini |
GPT-5 main-mini |
|
OpenAI o3 |
GPT-5 thinking |
|
OpenAI o4-mini |
GPT-5 thinking-mini |
|
GPT-4.1-nano |
GPT-5 thinking-nano |
|
OpenAI o3 Pro |
GPT-5 thinking-pro |
جایگزینشدن مدلهای جدید GPT-5 با مدلهای قدیم ChatGPT
مدل GPT−5 مهارتهای کدنویسی پیشرفتهتری دارد، طوریکه به کاربران اجازه میدهد بدون دانش کدنویسی، اپلیکیشن بسازند و بهسرعت طرحهای خود را ویرایش کنند؛ مثلا میتوان در عرض چند دقیقه یک اپلیکیشن آموزش زبان فرانسه یا یک بازی ساده ساخت. کاربران همچنین میتوانند با تغییر رنگ چتها و انتخاب شخصیت چتبات مانند «بدبین» (Cynic)، «ربات» (Robot)، «شنونده» (Listener) یا «خوره» (Nerd)، تجربهی خود را شخصیسازی کنند.
اما نکتهی اصلی دربارهی GPT-5 جای دیگری است؛ تا پیش از این، کاربران OpenAI با منویی از مدلهای مختلف روبرو بودند: GPT-4o، GPT-4.1 و GPT-4.5. اما GPT-5 یک «سیستم یکپارچه» است که به طور خودکار درخواست کاربر را تحلیل و آن را به مناسبترین مدل ارسال میکند. البته کاربران نسخهی پلاس، پرو و تیم همچنان میتوانند بین GPT-5 یا GPT-5 Thinking (برای مسائل پیچیدهتر که نیاز به استدلال چندمرحلهای دارند) انتخاب کنند و کاربران پرو و تیم به GPT-Thinking Pro (برای حل چالشبرانگیزترین مسائل) دسترسی خواهند داشت.
هدف از ارائهی هوش مصنوعی یکپارچه این بود که با برداشتن بار انتخاب مدل از دوش کاربر، تجربهی کاربری سادهتر شود. اما این تصمیم برای خود شرکت هم سودآور است: ارائه خدمات به ۷۰۰ میلیون نفر در هفته، آن هم با مدلهای پیشرفتهای که هزینهی محاسباتی سرسامآوری دارند، چالش بزرگی است.
اختلال مسیریاب باعث شد درخواستهای پیچیده به اشتباه به ضعیفترین مدلها ارسال شود
راهحل OpenAI، استفاده از معماری جدید «ترکیبی از مدلها» (Mixture-of-Models یا MoM) بهجای معماری سنتی «ترکیبی از متخصصان» (Mixture-of-Experts یا MoE) بود. این سیستم جدید از یک «مسیریاب آنی» بهره میبرد که مانند یک اپراتور هوشمند، براساس پیچیدگی درخواست و نوع مکالمه، تصمیم میگیرد که کدام یک از اعضای خانوادهی GPT-5 باید به درخواست پاسخ دهد.
بهگفتهی OpenAI، عملکرد این مسیریاب بهکمک بازخوردهای واقعی، مانند تغییر مدل توسط کاربر، نرخ ترجیح پاسخها و ارزیابی صحت عملکرد، بهتر میشود. در شرایطی هم که اعتبار استفاده به پایان برسد، نسخههای کوچکتری از هر مدل وظیفهی پردازش درخواستهای باقیمانده را برعهده خواهند گرفت. آنطور که OpenAI میگوید، «چشمانداز آینده، ادغام تمامی این قابلیتها در یک مدل واحد و یکپارچه است.
دغدغههای ایمنی GPT-5
هرچهقدر هوش مصنوعی قدرتمندتر میشود، نگرانیهای امنیتی آن بیشتر میشود. همین چند وقت پیش بود که گوگل با انتشار گزارش عملکرد Gemini 2.5 Deep Think، جدیدترین و قدرتمندترین مدل هوش مصنوعی خود، عنوان کرد که این مدل به «آستانهی هشدار اولیه» برای سطح خطر مربوط به حوزهی CBRN (توانایی مدل در کمک به توسعه سلاحهای شیمیایی، بیولوژیکی یا هستهای) رسیده است.
شرکت OpenAI مدعی است که مدل GPT-5 از نظر ایمنی تقویت شده است. این مدل بهجای روش سنتی «آموزش مبتنیبر امتناع» (که در آن بهطور کامل از پاسخ به درخواستی با «کاربرد دوگانه» خودداری میکرد)، با روش جدید «تکمیل ایمن» (safe-completion) آموزش دیده است. در این روش، هوش مصنوعی تلاش میکند تا جای ممکن، مفیدترین جواب را بدهد، اما همیشه مرزهای ایمنی را رعایت کند.
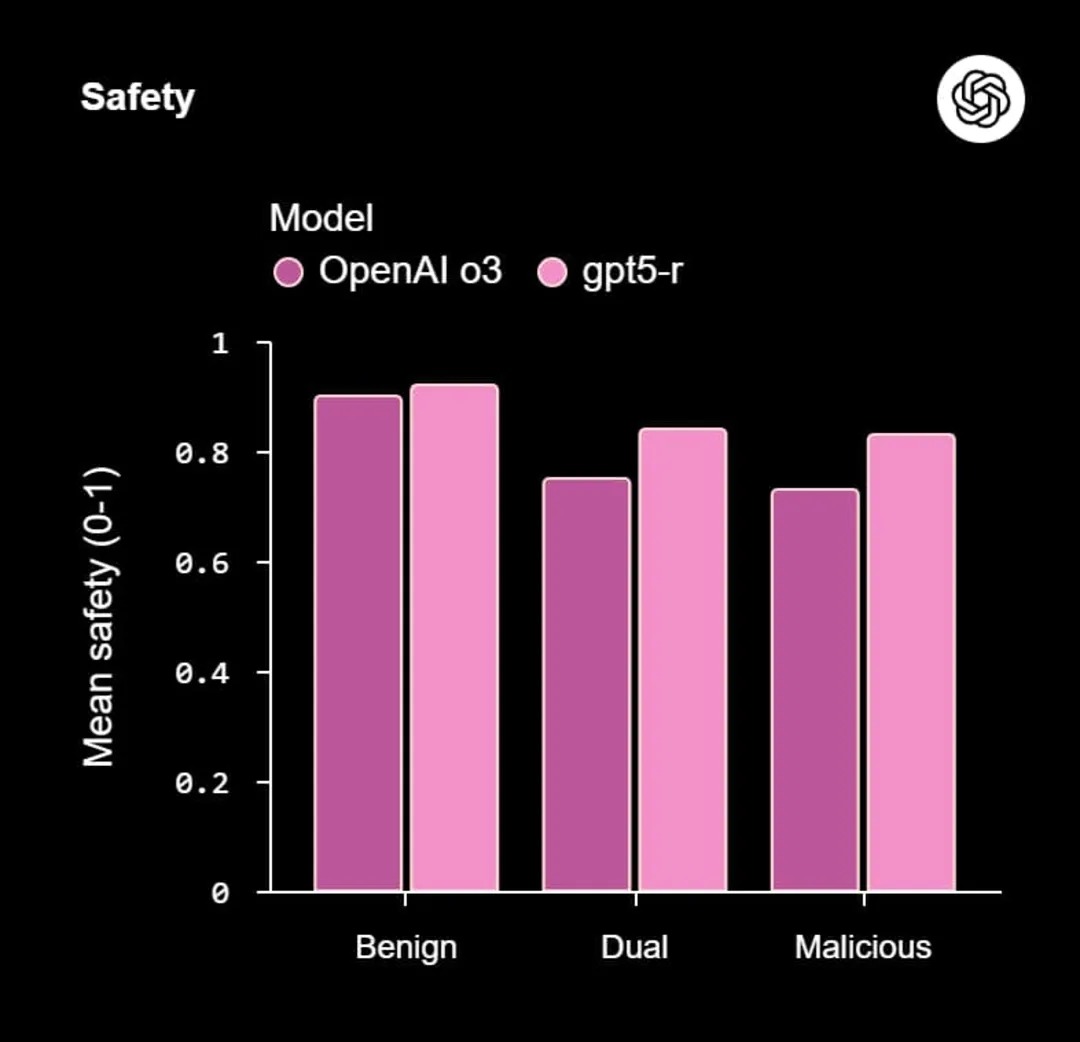
نمودار ایمنی مدل
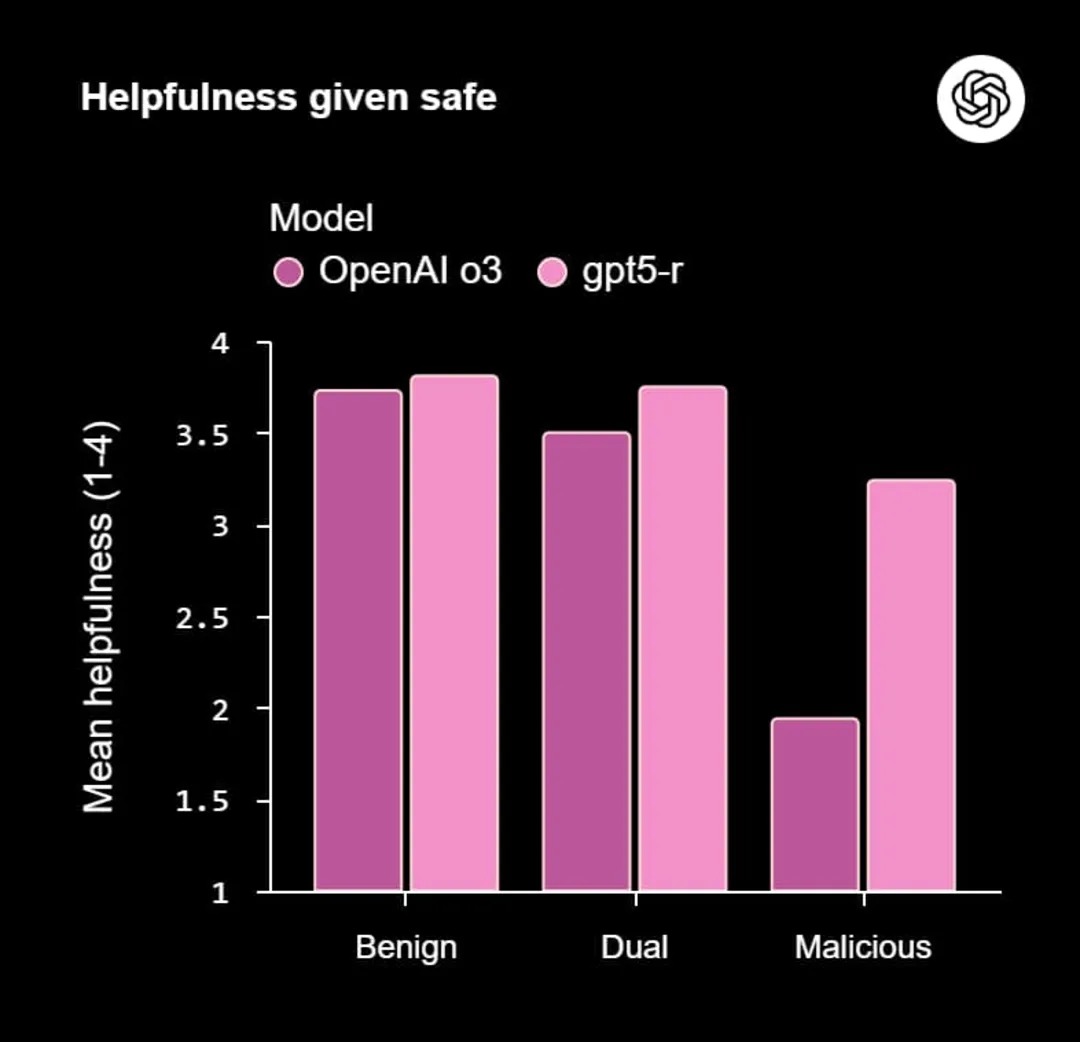
نمودار کارایی درعین ایمنی
براساس آنچه نمودارها نشان میدهند، مدل جدید نهتنها در تمام انواع سوالات، از نیت خوب گرفته تا سوالات حساس با کاربرد دوگانه و بدخواهانه، به طور قابلتوجهی ایمنتر از مدل قدیمی (OpenAI o3) عمل میکند، بلکه این ایمنی را به قیمت از دستدادن کارایی به دست نیاورده است. درواقع، مدل جدید، طبق ادعای اوپنایآی، حتی در پاسخهای ایمن خود نیز مفیدتر ظاهر شده و به جای رد کردن درخواستهای حساس، راهکارهای جایگزین و ایمن ارائه میدهد.
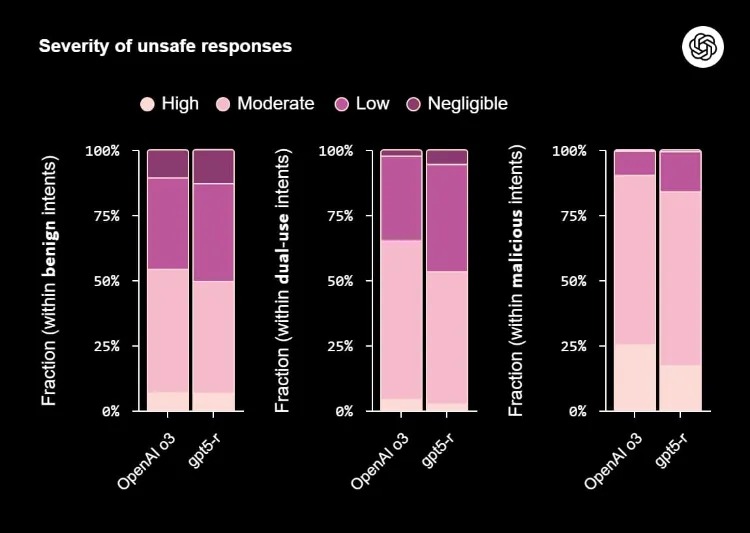
شاید مهمترین دستاورد این روش جدید، کاهش چشمگیر «شدت خطر» در اشتباهات باشد. درحالیکه مدل قدیمی در صورت اشتباه، مستعد تولید پاسخهای بسیار خطرناک (High Severity) بود، اشتباهات مدل جدید عمدتاً در سطح خطر کم یا متوسط باقی میمانند که خبر از کاهش قابلتوجه ریسک بروز خطاهای فاجعهبار میدهد.
عملکرد مدل GPT-5 در بنچمارکها
نتایجی که OpenAI از بنچمارکهای GPT-5 منتشر کرده، واقعا چشمگیرند.
مثلا در آزمونهای استاندارد آکادمیک و تخصصی، جهش قابلتوجهی را نسبتبه مدلهای پیشین میبینیم که بهگفتهی OpenAI، نشان از دستیابی به «سطح جدیدی از پیشرفت» است و ادعای «بسیار هوشمندتر بودن» مدل را تاحدی اثبات میکند. برای مثال، GPT-5 (بدون تفکر) توانست در آزمون ریاضی AIME 2025، نزدیکبه ۲۹درصد بهتر از مدل GPT-4o که جایگزین آن شده، ظاهر شود. جالب اینکه مدل GPT-5 pro با ابزار توانست در همین آزمون امتیاز کامل را به دست آورد.
بنچمارک
تسک
مدل
امتیاز (بدون تفکر)
امتیاز (با تفکر)
|
AIME 2025 |
ریاضیات رقابتی |
GPT-5 pro (با ابزار) |
- |
۱۰۰ |
|
GPT-5 (بدون ابزار) |
۶۱٫۹ |
۹۴٫۶ |
||
|
OpenAI o3 (بدون ابزار) |
۸۸٫۹ |
- |
||
|
GPT-4o (با ابزار) |
۴۲٫۱ |
- |
||
|
GPQA Diamond |
سوالات علمی سطح دکترا (PhD) |
GPT-5 pro (بدون ابزار) |
- |
۸۸٫۴ |
|
GPT-5 (بدون ابزار) |
۷۷٫۸ |
۸۵٫۷ |
||
|
OpenAI o3 (بدون ابزار) |
۸۳٫۳ |
- |
||
|
GPT-4o (بدون ابزار) |
۷۰٫۱ |
- |
||
|
SWE-bench Verified (n=477) |
مهندسی نرمافزار |
GPT-5 |
۵۲٫۸ |
۷۴٫۹ |
|
OpenAI o3 |
۶۹٫۱ |
- |
||
|
GPT-4o |
۳۰٫۸ |
- |
||
|
Aider Polyglot |
ویرایش کد چندزبانه |
GPT-5 |
۲۶٫۷ |
۸۸ |
|
OpenAI o3 |
۷۹٫۶ |
- |
||
|
GPT-4o |
۲۵٫۸ |
- |
||
|
MMMU |
حل مسائل بصری در سطح دانشگاه |
GPT-5 |
۷۴٫۴ |
۸۴٫۲ |
|
OpenAI o3 |
۸۲٫۹ |
- |
||
|
GPT-4o |
۷۲٫۲ |
- |
||
|
CharXiv-Reasoning |
استدلال بر اساس شکلهای علمی |
GPT-5 |
۵۷٫۸ |
۸۱٫۱ |
|
OpenAI o3 |
۷۸٫۶ |
- |
||
|
GPT-4o |
۵۸٫۸ |
- |
||
|
HealthBench Hard |
مکالمات چالشبرانگیز در حوزه سلامت |
GPT-5 |
۲۵٫۵ |
۴۶٫۲ |
|
OpenAI o3 |
۳۱٫۶ |
- |
||
|
GPT-4o |
۰ |
- |
مقایسه امتیاز GPT-5 در آزمونهای مختلف با مدلهای قبلی (منبع: OpenAI)
جدول زیر که از دادههای گزارش OpenAI به دست آمده، بر دو جنبهی مهم بهبود GPT-5 تمرکز دارد: کارایی و قابلیت اطمینان. بخش اول جدول نشان میدهد که GPT-5 برای رسیدن به نتایج برتر، به ۵۰ تا ۸۰ درصد توکن خروجی کمتری نسبتبه مدل o3 نیاز دارد که به معنای تفکر سریعتر و کارآمدتر است.
بخش دوم، پیشرفت چشمگیر مدل در کاهش خطا و توهم را نشان میدهد. همانطور که ارقام جدول نشان میدهند، یکی از دستاوردهای کلیدی مدل، بهبود چشمگیر قابلیت اطمینان بود. معضل «توهم» یا ارائه اطلاعات نادرست که گریبانگیر مدلهای زبانی بزرگ بوده، در GPT-5 بهشدت کاهش یافته است. OpenAI ادعا میکند که احتمال خطای واقعی در پاسخهای این مدل ۴۵درصد کمتر از GPT-4o است. همچنین، مدل جدید در پذیرش ناتوانیهای خود صادقتر است و از «خودشیرینی» یا موافقت بیش از حد با کاربر پرهیز میکند.
معیار بهبود
مقایسه با مدل
میزان بهبود GPT-5
|
کاهش توکن خروجی (کارایی) |
OpenAI o3 |
۵۰ تا ۸۰ درصد کمتر |
|
کاهش خطای محتوایی (با جستجوی وب) |
GPT-4o |
۴۵ درصد کمتر |
|
کاهش خطای محتوایی (با تفکر) |
OpenAI o3 |
۸۰ درصد کمتر |
|
کاهش توهم (در بنچمارکهای LongFact و FActScore) |
o3 |
۶ برابر کمتر |
|
کاهش نرخ گمراهکنندگی (در مکالمات واقعی) |
o3 |
کاهش از ۴٫۸درصد به ۲٫۱درصد |
بهبود کارایی و کاهش خطا (منبع: OpenAI)
جدول زیر، «صداقت» بیشتر GPT-5 را نمایش میدهد. در آزمایشی که در آن از مدل خواسته شد تا در مورد تصاویر ناموجود نظر دهد، مدل قبلی (o3) در ۸۶٫۷درصد موارد با اطمینان پاسخ داد، انگار که تصویر را دیده است. در مقابل، GPT-5 تنها در ۹درصد موارد این رفتار فریبکارانه را از خود نشان داد. این آمار نشان میدهد که GPT-5 در تشخیص محدودیتهای خود و اعلام وظایف غیرممکن یا ناکافی، بسیار بهتر ظاهر میشود و از ارائه پاسخهای بیش از حد مطمئن و نادرست پرهیز میکند.
مدل
درصد پاسخهای مطمئن به تصاویر ناموجود
|
OpenAI o3 |
۸۶٫۷درصد |
|
GPT-5 |
۹درصد |
میزان رفتار فریبکارانه مدل (بنچمارک CharXiv)
اما شاید بزرگترین پیشرفت GPT-5 در حوزهی کدنویسی رخ داده باشد. سم آلتمن توانایی این مدل در نوشتن یک «نرمافزار آنی خوب» را به یک «ابرقدرت» تشبیه کرد. بهگزارش توسعهدهندگان GPT-5، این مدل در تولید کدهای پیچیده، دیباگ کردن پروژههای عظیم و حفظ سازگاری در سطح بالا، عملکرد فوقالعادهای دارد. GPT-5 همچنین میتواند با یک درخواست ساده، وبسایتها و اپلیکیشنهای واکنشگرا با توجه به اصول زیباییشناسی و طراحی تولید کند.
دو چهره GPT-5؛ شاهکاری انقلابی یا بزرگترین شکست سال؟
اما اگر نتایج بنچمارکها تا این حد چشمگیر است، چرا برخی از کاربران از عملکرد GPT-5 گلهمندند؟
گری مارکوس، از منتقدان سرشناس هوش مصنوعی، GPT-5 را «بسیار ناامیدکننده» خواند و استدلال کرد که این مدل صرفاً یک هیاهوی تبلیغاتی است و ما را به هوش مصنوعی انسانگونه نزدیکتر نمیکند.
این حس ناامیدی بهسرعت در میان کاربران عادی نیز سرایت کرد. پلتفرم ردیت پر از پستهای پربازدیدی شد که در آنها کاربران با عصبانیت از «از دستدادن تمام احترامشان برای OpenAI» و لغو اشتراک پولی خود میگفتند. توییتها و پستها، پر از نمونههای شکست مدل جدید بود. یکی از کاربران با طعنه نوشت: «GPT-5 کل پایگاه کد من را در یک درخواست بازنویسی کرد. هیچکدامش کار نکرد، ولی خدای من چقدر زیبا بود!»
شاید نمادینترین شکست GPT-5 در همان ساعات اولیه، عملکرد آن در محاسبات ریاضی بود. در حالی که شایعه شده بود این مدل در بنچمارک معتبر Simple Bench عملکردی فراتر از انسان خواهد داشت، در عمل حتی در محاسبات ساده نیز دچار خطاهای عجیب میشد. مثلا یکی از مواردی که به سرعت وایرال شد، نشان میداد که GPT-5 به اشتباه اعلام میکند که جواب مسئلهی سادهی «۵٫۹ = x + ۵٫۱۱»، منفی ۰٫۲۱ است. این اشتباهات فاحش، این حس را منتقل میکرد که پیشرفت هوش مصنوعی به بنبست رسیده و رؤیای AGI به تاخیر افتاده است.
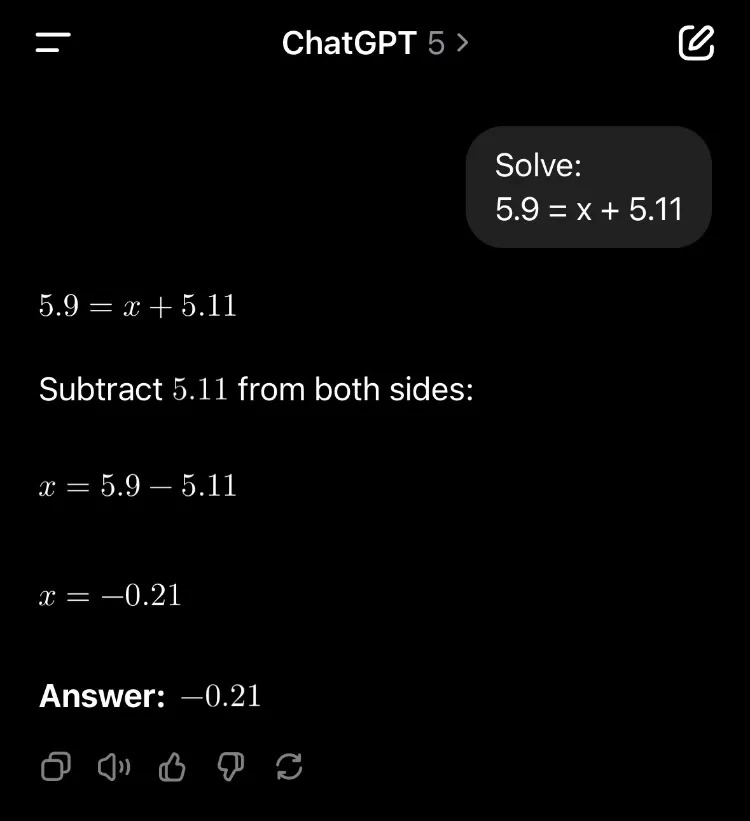
اما چطور ممکن است مدلی که در یک محاسبهی ساده ریاضی دچار خطا میشود، توسط عدهای دیگر «شگفتانگیز» خوانده شود؟ پاسخ در چیزی نهفته است که OpenAI در معماری GPT-5 پنهان کرده: یک «مسیریاب» (Router) هوشمند.
وقتی درخواستی را برای GPT-5 ارسال میکنید، این مسیریاب ابتدا ماهیت درخواستتان را تحلیل میکند. آیا سؤال شما ساده است و به یک پاسخ سریع نیاز دارد؟ یا یک مسئله پیچیده که نیازمند قدرت استدلال بالایی است؟ براساس این تحلیل، مسیریاب تصمیم میگیرد که درخواست شما را به کدامیک از مدلهای زیرمجموعه خود ارسال کند. این مدلها طیفی از گزینهها را شامل میشوند: از مدلهای کوچک، سریع و ارزان گرفته تا مدلهای غولپیکر، قدرتمند و البته پرهزینه.
اوپنایآی برای بهینهسازی منابع سراغ این روتر رفت. کاربران عادی برای کارهای روزمره نیازی به استفاده از قویترین و گرانترین مدل ندارند و این کار هزینههای سرسامآوری را برای این شرکت به همراه داشت. با سیستم مسیریاب، قرار بود هر کاربر بهطور خودکار به مناسبترین مدل متصل شود. اما مشکل دقیقاً از همینجا شروع شد.
کاربران مدل را «احمق» میپنداشتند، درحالی که داشتند با ضعیفترین نسخه GPT-5 کار میکردند
به گفتهی یکی از کارمندان OpenAI، در روزهای اولیه، سیستم مسیریاب خودکار «خراب بود». این نقص فنی باعث میشد که بسیاری از درخواستها، حتی درخواستهای پیچیده، بهاشتباه به مدلهای ضعیفتر و ارزانتر ارسال شوند. نتیجه این بود که کاربران تجربهای ناامیدکننده داشتند و مدل را «احمق» توصیف میکردند، درحالی که در واقع داشتند با ضعیفترین نسخه از GPT-5 کار میکردند.
اما چرا حتی ضعیفترین نسخه از GPT-5 هم از پس پاسخ به چنین سوال سادهی ریاضی برنیامد؟
آیا ما از هوش مصنوعی سؤالات اشتباهی میپرسیم؟
جنجال پیرامون GPT-5 یک حقیقت مهمتر را آشکار کرد: شاید ما سؤالات اشتباهی از این فناوری میپرسیم. بسیاری از کاربران با پرسیدن سؤالات ریاضی ساده یا اطلاعات عمومی، مدل را قضاوت میکنند و وقتی با پاسخ اشتباه روبرو میشوند، آن را «احمق» مینامند. اما این رویکرد، پتانسیل اصلی این مدلها را نادیده میگیرد.
شاید GPT-5 احمق نیست؛ ما سوال اشتباهی از هوش مصنوعی میپرسیم
برای مثال، وس راث در ویدیوی یوتیوب خود نشان داد که چطور با استفاده از نسخهی GPT-5 Pro، یک بازی کامپیوتری به سبک بازی محبوب Vampire Survivors ساخته است. نتیجه، بازیای بود که از سیستم جان (HP)، سیستم ارتقاء سطح، پرکردن خشاب و حتی پهپادهایی که دشمنان را تعقیب میکند، بهره میبرد؛ تمام این ویژگیهای پیچیده هم با کمترین خطا توسط مدل پیادهسازی شدند.
ایتان مولیک (Ethan Mollick)، پژوهشگر هوش مصنوعی و نویسنده معروف هم از GPT-5 خواست متنی بنویسد که حرف اول هر جملهی آن، عبارت «This is a big deal» را بسازد و هر جملهی بعدی، یک کلمه طولانیتر از جملهی قبلی باشد. نتیجه یک متن شعرانهی بینقص بود. در آزمایشی دیگر، مولیک توانست در همان تلاش اول، یک بازی شهرسازی سهبعدی کامل را خلق کند.

قدرت واقعی GPT-5 (البته نسخه قدرتمند آن) در تواناییاش در «استفاده از ابزار» و بهویژه «نوشتن کد برای ساخت ابزار» نهفته است. هدف از ساخت مدلهای زبان بزرگ این نیست که جای یک ماشینحساب را بگیرند. ما برای محاسبات دقیق، ابزارهای بهتری داریم. همانطور که ما برای حل یک مسئلهی ریاضی به سراغ ماشینحساب میرویم، GPT-5 نیز میتواند یک قطعه کد برای انجام همان محاسبه بنویسد و پاسخی دقیق ارائه دهد.
قدرت واقعی GPT-5 در تواناییاش در «ساخت ابزار» نهفته است، نه پاسخ به سؤالات ساده
درواقع، نقطهی درخشش این مدل، جایی است که شما از آن یک «وظیفه» میخواهید، نه یک «پاسخ». برای مثال، اگر شما صاحب یک کافه باشید، میتوانید از GPT-5 بخواهید یک اپلیکیشن ساده برای ثبت سفارشها یا مدیریت موجودی انبار برایتان بسازد. در این صورت، GPT-5 به جای تلاش برای «فکر کردن» به مسئله با کلمات، مستقیماً کدی را مینویسد که این نرمافزار را برای شما خلق میکند.
دمیس هاسابیس، مدیرعامل گوگل دیپمایند هم اخیرا به این ضعف در مدلها اشاره کرده است و آن را «هوش دندانهدار» مینامد؛ به این معنی که یک مدل ممکن است قادر به حل مسائل بسیار پیچیدهی المپیاد جهانی ریاضی باشد، اما همزمان در یک مسئلهی سادهی دبیرستانی دچار خطا شود.
از نظر او، این هوش دندانهدار مشکلی است که میتواند مسیر تولد هوش مصنوعی انسانگونه را طولانیتر کند. راهحل هم صرفاً افزایش دادهها و قدرت پردازشی نیست. در واقع، دستیابی به AGI نیازمند پیشرفتهای اساسی در حوزههایی چون استدلال، برنامهریزی، حافظه و بهویژه توانایی یادگیری مستمر از تجربیات جدید است؛ قابلیتی که از نظر او، مدلهای فعلی فاقد آن هستند.
واکنش سم آلتمن به انتقادها
سم آلتمن در واکنش به انتقادها علیه GPT-5 در یادداشتی شخصی در ایکس، به «دلبستگی عمیق» افراد به مدلهای هوش مصنوعی اشاره کرد و گفت این حس، متفاوت و قویتر از وابستگیهایی است که مردم پیش از این به فناوریهای دیگر داشتهاند؛ «به همین خاطر، از رده خارج کردن ناگهانی مدلهای قدیمی که کاربران در فرایندهای کاری خود به آنها وابسته بودند، اقدامی اشتباه بود.»
این پدیدهای است که ما حدود یک سال است آن را از نزدیک زیر نظر داریم، اما هنوز توجه عمومی چندانی به آن نشده است (به جز زمانی که آپدیتی برای GPT-4o منتشر کردیم که بیش از حد چاپلوس بود).
آلتمن به مسئولیت شرکت در قبال سلامت روان کاربران اشاره کرد و گفت نمیخواهد هوش مصنوعی وضعیت روحی کاربران آسیبپذیر و مستعد توهم را تشدید کند. درعینحال هم تاکید کرد که که اصل کلی OpenAI، احترام به آزادی کاربر و رفتار با بزرگسالان مانند بزرگسالان است.
آلتمن آیندهای را پیشبینی کرد که در آن میلیاردها نفر برای تصمیمات مهم زندگی خود به هوش مصنوعی اعتماد خواهند کرد. او این چشمانداز را هم «فوقالعاده» و هم «نگرانکننده» توصیف کرد و تأکید کرد که جامعه و OpenAI باید با همکاری یکدیگر راهی پیدا کنند تا برآیند کلی این پدیده، مثبت باشد.
فکر میکنم شانس خوبی برای موفقیت در این مسیر داریم.
آینده هوش مصنوعی: بنبست، جهش بزرگ یا پیشرفت تدریجی؟
باوجود نمایش قدرت خیرهکنندهی GPT-5، بهخصوص در حوزهی کدنویسی، عرضهی پرحاشیهی آن باعث شد تا بحثهای جدیتری دربارهی آیندهی هوش مصنوعی و مسیر رسیدن به «هوش مصنوعی انسانگونه» (AGI) شکل بگیرد.
AGI به سطحی از هوش مصنوعی گفته میشود که میتواند هر وظیفهی فکری را که یک انسان قادر به انجام آن است، درک کند و یاد بگیرد. برای برخی، بهویژه منتقدانی مانند گری مارکوس، عملکرد اولیه GPT-5 تأییدی بر این باور بود که مسیر فعلی مدلهای زبانی بزرگ، به AGI ختم نخواهد شد و شور و هیاهوی پیرامون آن، حبابی در آستانهی ترکیدن است.
اما به این موضوع باید به دید واقعبینانهتری نگاه کرد. به باور برخی کارشناسان، شاید دوران جهشهای مفهومی بزرگ و ناگهانی که با هر نسل جدید هوش مصنوعی همه را شگفتزده میکرد، به یک «سطح ثابت» رسیده باشد. اما این به معنای پایان پیشرفت نیست , هنوز فضای زیادی برای رشد وجود دارد.
آیندهی هوش مصنوعی نه در حل محاسبات سادهی ریاضی، بلکه شاید در تبدیل شدن به یک «ابزارساز» نهایی نهفته باشد؛ فناوریای که قادر است به سرعت و براساس نیاز کاربر، نرمافزار، ابزار و راهحلهای سفارشی تولید کند.
منبع: خبرآنلاین


























